Better learning and engagement in a MOOC using ML & AI
Edraak, an initiative of the Queen Rania Foundation, is the largest MOOC (Massive Online Open Course) in the Arabic language, providing learning opportunities to millions of users. Using Artificial Intelligence (AI) powered solutions from Daemon, Edraak is bringing state of the art Machine Learning (ML) to the service of their users, improving the likelihood they will find and engage with appropriate material and ultimately benefit from it.
The challenge
Edraak’s aim is mainly to be of service to the Arabic speaking community and instrumental in its continued intellectual development. As such, Edraak is constantly seeking ways to connect its users with subject matter that will benefit them and also to ensure its users are successful in their learning.
After an initial discovery phase, Daemon investigated Edraak’s platform, data, and approach, and a set of ways in which ML & AI could contribute to Edraak’s core goals were presented. Of these, a handful were chosen to be developed into solutions ready for Edraak to use to the advantage of its users:
- Learning system: For predicting whether users will continue to interact with a course, or if they need remedial action. ‘At risk’ users would be flagged and potentially followed up automatically, for example, by email.
- Recommender system: A system for recommending courses that learns from the past behaviour of users.
- Recommendations endpoint: A recommendations endpoint for obtaining smart user recommendations online that can be displayed in real time to Edraak's users.
- Automated learning pipelines: For extracting live data, learning from it, evaluating the capability system online and creating dashboards to display the data.
- Transcribe and Translate tool: For automatically transcribing and translating course videos, to increase the accessibility of material, subsequent engagement of users, as well as improving SEO.
Our Approach
Careful empirical investigation
Machine Learning is different from other kinds of software development in that there is always more uncertainty at the start, but we know how to manage this uncertainty. Before building prototypes or moving processes into production, we decided how to measure our performance, trained some machine learning models, and ensured that the results were good enough to move on to the next stage.
Building a learning dropout predictor
This machine learning system aims to find the probability that a user will not finish a course in the future. For our dropout prediction system we examined the data available to us carefully to understand how well it reflected the historical record of user actions: can we determine when exactly the dropout occurred? Can we trust this historical data to provide us an insight into how well our system is working? We designed around the gaps in the data to create an online system that adjusts its learning and estimate of performance as newer data becomes available. The dropout prediction is designed to be run as a batch process flowing into further actions to be taken on ‘at risk’ users, such as targeted emails.
Building a learning course recommender
For our course recommender system we designed a machine learning model that learnt to predict courses that users are likely to be successful in - for example, the user completing a course - based on the history of the user in the MOOC. The machine learning model tries to learn the following relationship:
![]()
Taking this core system and using it in a recommender involved building around it logic to provide sufficient diversity, and balance over different courses, including new courses for which we don’t yet have enough data for the learning system.
Building a recommender endpoint
We wrapped the trained recommender model using Google Cloud Functions with our recommender logic for ensuring diversity and balance in predictions, providing our own HTTP endpoint.
Building a training pipeline
For both dropout prediction and recommender systems, we used a solution 100% within the Google Cloud ecosystem, using the Google Cloud Platform tools for orchestration, scalable and cheap extraction, transformation and loading of data, machine learning training, post processing, and dashboarding.
Outcome
We built an end-to-end training pipeline, dashboard and endpoint architecture 100% within Google Cloud. The pipeline and dashboard, similar in both models, as well as the HTTP endpoint for the recommender system, are shown below:
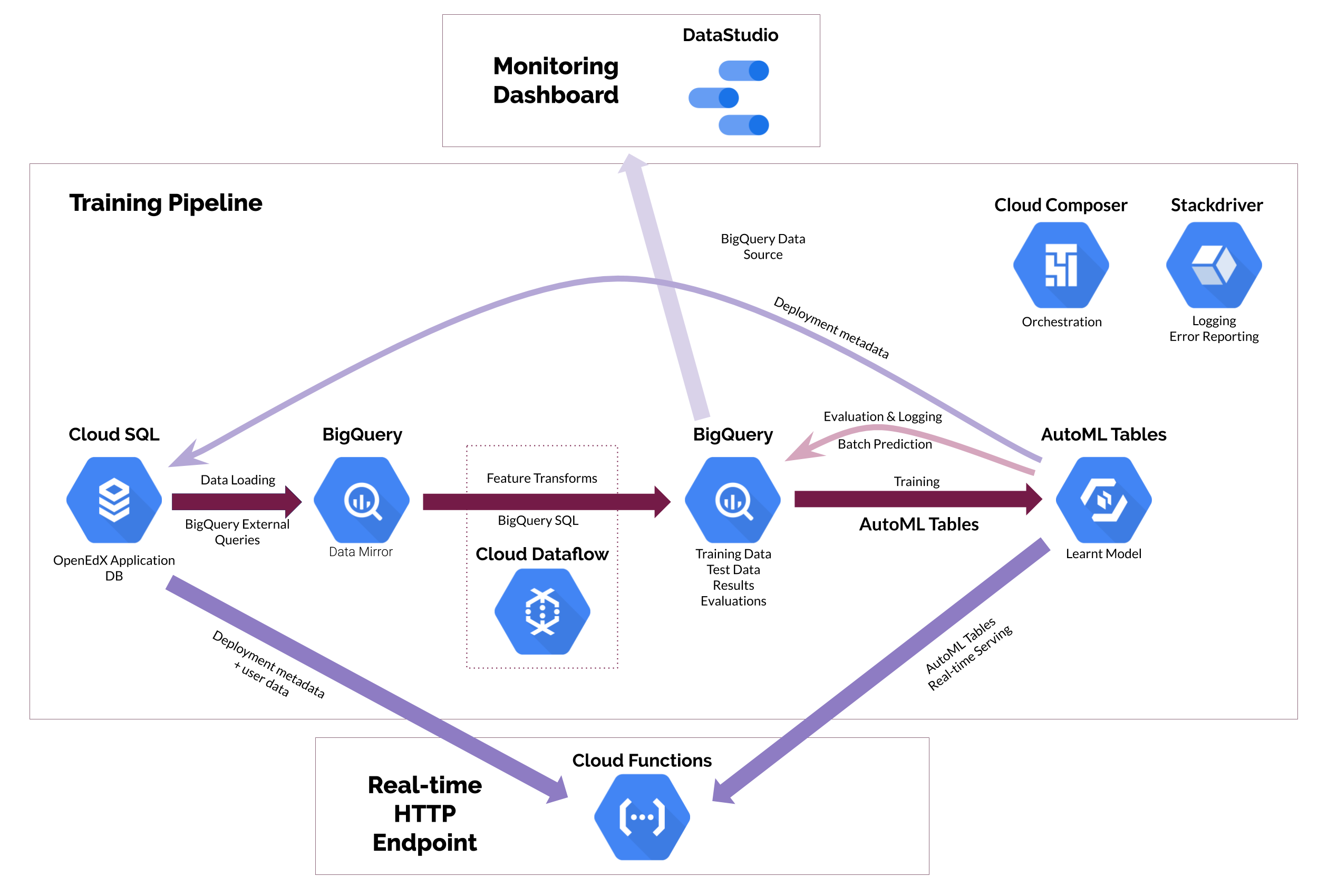
Results
- A recommender that is AI optimised for finding users courses in which they are likely to be successful.
- 100% diversity and 100% balance in recommendations using smart post-processing.
- Highly accurate dropout prediction - estimated accuracy of 97% 1-8 weeks post enrolment.
- Foundations in place for automated follow-up of at-risk users and KPI monitoring.
- Ability to refine and improve predictions over time.
Need help turning your information into intelligence?
