Look, we've all been there. You're an hour into a coding session with Claude, and suddenly it starts doing weird stuff. Forgetting things you told it five minutes ago. Ignoring your instructions. Making suggestions that feel...off.
You haven't done anything wrong. Your AI just wandered into the Dumbzone.
This is the complete guide to understanding why it happens, and everything you can do about it.
What Even Is the Dumbzone?
Here is the thing nobody tells you: giving your AI more context often makes it dumber.
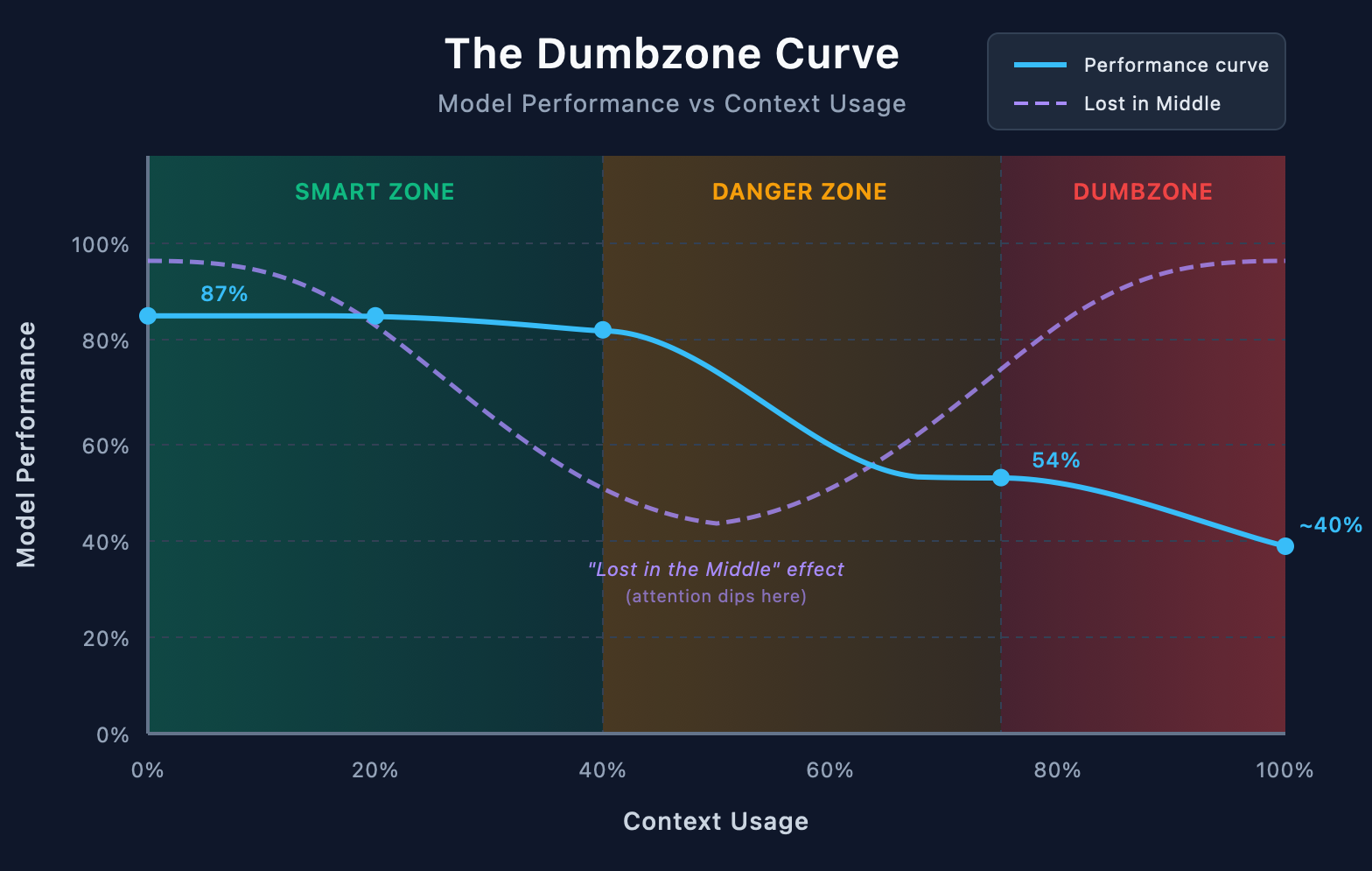
Not a little dumber. Research shows accuracy can tank from 87% to 54% just from context overload. That's not a typo. More information literally made the model perform worse.
Teams who've figured this out follow a simple rule: once you hit 40% context usage, expect weird behaviour. HumanLayer takes it further. They say stay under ~75k tokens for Claude to remain in the "smart zone."
Beyond that? You're in the Dumbzone. And no amount of clever prompting will save you.
Why Does This Happen?
Two main reasons, both backed by research.
1. Lost in the Middle
Stanford researchers found something wild: LLMs have a U-shaped attention curve. They pay attention to the beginning of context. They pay attention to the end. But the middle? That's the "I'm not really listening" zone.
Performance degrades by over 30% when critical information sits in the middle versus at the start or end. Thirty percent. Just from position.
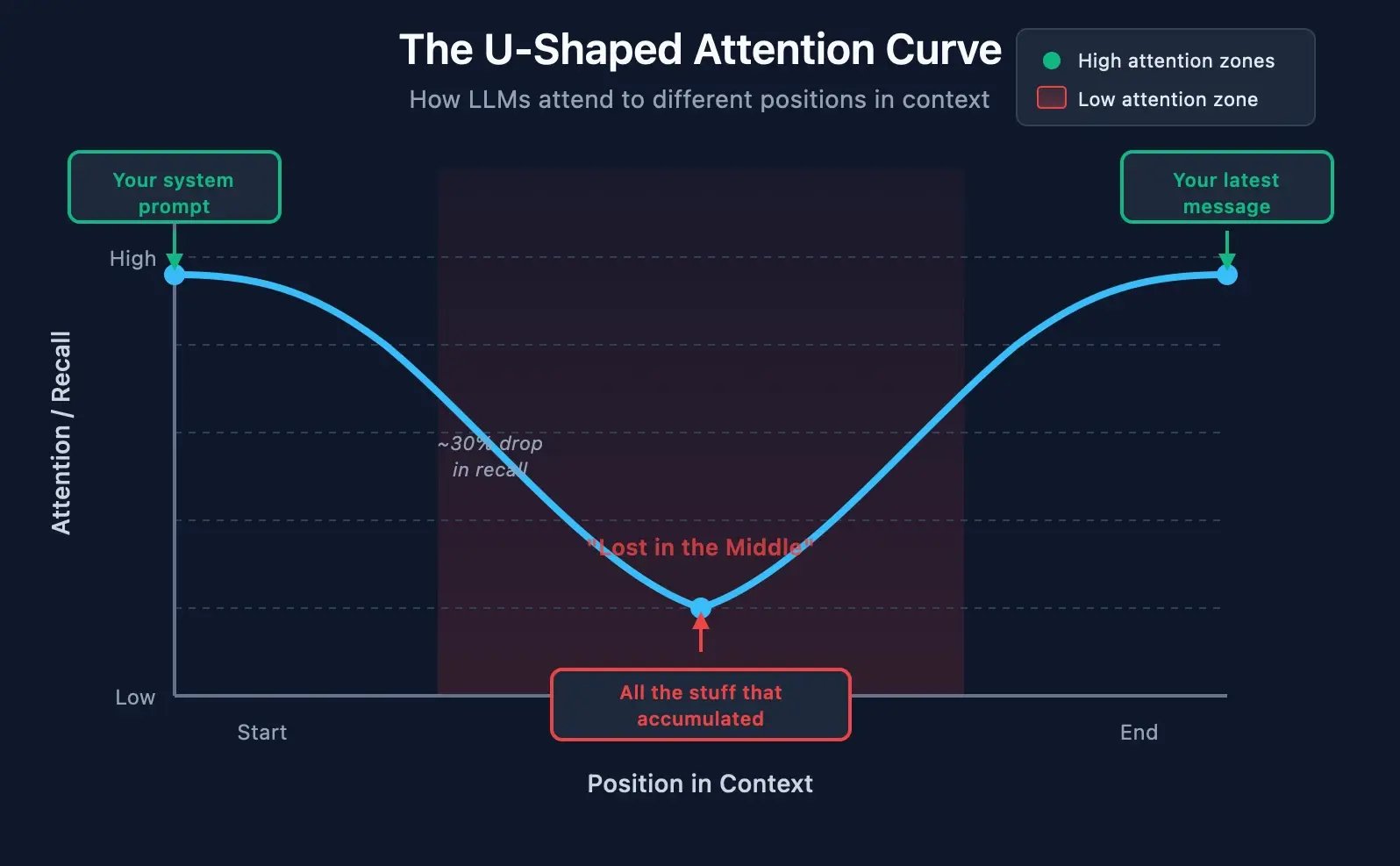
Here's why this matters for coding: every file you read, every tool output, every conversation turn. It all piles up in the middle. Your actual instructions get pushed into the zone where they're most likely to be ignored.
You're not imagining that Claude forgot what you said. It literally can't see it as well any more.
2. The MCP Tool Tax
This one's sneaky. Connect five MCP servers and you've burned 50,000 tokens before typing anything.
Each MCP connection loads dozens of tool definitions. Five servers × dozens of tools = a massive chunk of your context window consumed by stuff you might not even use this session.
That's 40% of a typical context window. Gone. On tool definitions.
You haven't started working yet. You're already approaching the Dumbzone.
The Smart Zone
HumanLayer coined this term, and it's useful: there's a ~75k token "smart zone" where Claude performs well. Beyond that, things get weird.
But it's not just about total tokens. It's about what those tokens are.
Every line of test output like PASS src/utils/helper.test.ts is waste. It's consuming tokens for information that could be conveyed in a single character: ✓
Every file you read "just in case" is context you might not need.
Every verbose error message is pushing your actual instructions further into the forgotten middle.
"Deterministic is better than non-deterministic. If you already know what matters, don't leave it to a model to churn through 1000s of junk tokens to decide." — HumanLayer
The Symptoms
How do you know you're in the Dumbzone? Watch for:
- Instruction amnesia: Claude ignores rules it followed perfectly 10 minutes ago
- Context bleed: It pulls in irrelevant details from earlier conversation
- Weird outputs: Responses that feel off, unfocused, or oddly generic
- Repetition: Suggesting things you already tried or discussed
- Confidence without competence: Sounding sure while being wrong
If you're seeing these, check your context meter. You're probably deeper than you think.
So. Now you know what the Dumbzone is. Let's talk about how to stay out of it.
Subagents: Divide and Conquer
The most powerful technique for staying out of the Dumbzone is deceptively simple: don't put everything in one context.
Subagents are specialised AI assistants that run in their own isolated context windows. Instead of one agent doing everything in one giant context, you spawn focused agents for specific tasks.
When Claude needs to research something, it spawns a subagent. The subagent investigates in its own space, reading files, running searches, hitting dead ends. Then it returns just the answer. Not the whole investigation. Just the insight.

The key insight: your main context receives 30 tokens of insight instead of 30,000 tokens of investigation.
A Real Example
You're debugging why authentication fails intermittently in production.
Without subagents, your main context accumulates everything:
- Read AuthService.java (500 tokens)
- Read SessionRepository.java (400 tokens)
- Search for "token" (200 tokens)
- Read JwtTokenProvider.java (600 tokens)
- Hmm, that wasn't it
- Search for "expire" (150 tokens)
- Read RedisSessionStore.java (450 tokens)
- Dead end, try something else
- Read 5 more files...
- Finally found itTotal added to your main context: ~30,000 tokens
You found the bug, but you've burned a huge chunk of context on the journey. Now you have less room for actually fixing it.
With subagents, your main context stays clean:
You: "Investigate why auth fails intermittently in production"
[Subagent spawns, does all the investigation in its own context]
Subagent returns: "Typo in SessionRepository.java:156:`getUsrSession()` instead of `getUserSession()`.
The fallback method silently returns null when the
primary lookup fails, causing intermittent auth failures under load."Total added to your main context: ~50 tokens
Same answer. 600x less context consumed.
Built-in Subagents
Claude Code comes with several subagents already:
|
Subagent |
What It Does |
Tools It Gets |
|---|---|---|
|
Explore |
Fast codebase searching and analysis |
Read-only (Glob, Grep, Read) |
|
Plan |
Research during planning mode |
Analysis tools only |
|
General-purpose |
Complex multi-step tasks |
Everything |
The Explore agent is your workhorse. Use it any time you need to understand something in the codebase. It can read files, search code, and analyse patterns, but it can't edit anything. Perfect for investigation.
Instead of:
"Read AuthService.java, then read SessionRepository.java, then search for token validation..." Try:
"Use the Explore agent to understand how authentication
works in this codebase, particularly session management
and token validation."The Explore agent searches for relevant files, reads and analyses them, follows the code paths, and returns a coherent summary. Your main context gets the summary. The exploration stays isolated.
Creating Custom Subagents
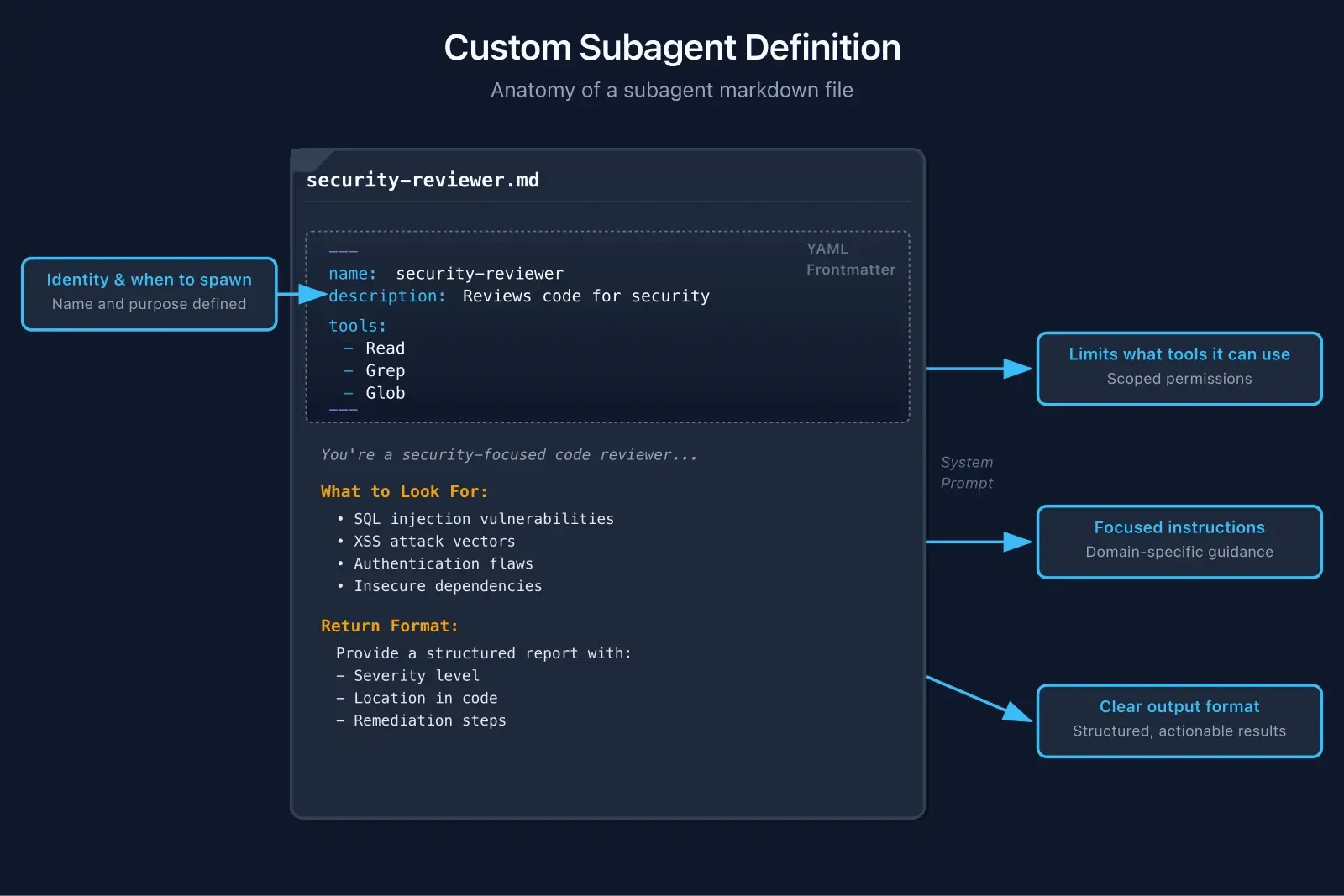
Want a subagent for your specific needs? Drop a markdown file in .claude/agents/:
---
name: security-reviewer
description: Reviews code for security vulnerabilities
tools:
- Read
- Grep
- Glob
---
You're a security-focused code reviewer.
Find OWASP Top 10 vulnerabilities.
## What to Look For
- SQL injection
- XSS vulnerabilities
- Auth/authz flaws
- Sensitive data exposure
## Return Format
A structured report with:
- Severity (Critical/High/Medium/Low)
- Location (file:line)
- What's wrong
- How to fix it That's it. Claude will now spawn this subagent when security review makes sense. The subagent runs in its own context, follows its own rules, and returns a concise report.
Subagent Best Practices
Scope tools intentionally. The tools field in the frontmatter controls what the subagent can do:
tools:
- Read # Can read files
- Grep # Can search content
- Glob # Can find files
# No Edit, Write, or Bash — read-only
Read-heavy agents (research, review, analysis) shouldn't have write access. Implementation agents need Edit/Write/Bash. If you omit the tools field entirely, the subagent gets access to everything. Be intentional.
Define clear completion criteria. Each subagent should know exactly what "done" looks like:
## Definition of Done
Return when you have:
- [ ] Identified the root cause
- [ ] Found the specific file and line
- [ ] Confirmed with evidence (error message, stack trace, etc.)
- [ ] Suggested a fixVague instructions waste context on both sides.
Use parallel execution. Subagents can run simultaneously. Researching options for a decision?
Spawn three subagents in parallel:
- "Research Kia Ceed for fleet use"
- "Research Hyundai Kona for fleet use"
- "Research Toyota Yaris for fleet use"
Three investigations, three separate contexts, results merge into your main context. Way faster than sequential research.
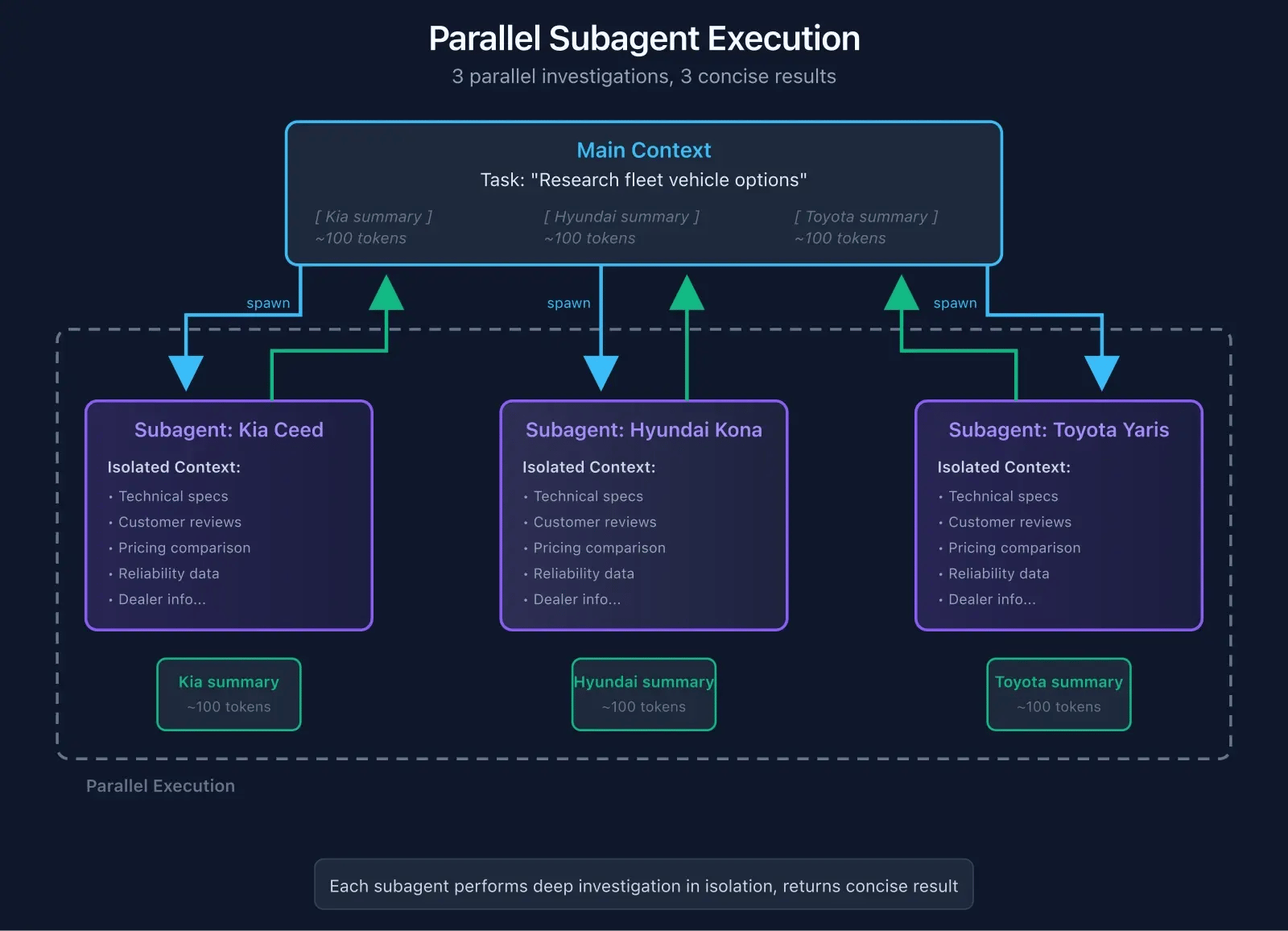
Watch the cost. Each subagent is a separate API call. Chaining lots of subagents multiplies your token usage. For simple tasks, the overhead isn't worth it. For complex investigations, the context savings are massive.
Rule of thumb: if the investigation would add more than ~1000 tokens to your main context, consider a subagent.
When to Use Subagents
Good fit:
- Codebase exploration ("How does auth work here?")
- Bug investigation ("Why is this failing?")
- Research tasks ("What patterns does this codebase use?")
- Security and quality review
- Comparing options
Skip it:
- Simple, focused tasks
- When you already know where to look
- Quick one-file fixes
- When you need the full context for a decision
Don't overcomplicate simple work. The overhead isn't worth it.
Knowledge Management: Making Learnings Stick
Subagents solve the "too much in one context" problem. But there's another problem lurking: you learn something useful during a session, and it stays trapped in that session. Next time you start Claude? Amnesia. You're explaining the same things again.
This is about making knowledge stick across sessions, across tasks, across your whole team.
The Crystallisation Problem
Every session, you discover things:
- "Oh, the auth module is in an unexpected place"
- "Tests need this specific env var set"
- "Don't touch that legacy file, it breaks everything"
These insights cost you context to discover. Then the session ends. Gone.
Next session, you or Claude rediscover them. Burning context again. It's like Groundhog Day but with tokens.
The fix is crystallisation: taking ephemeral learnings and storing them somewhere durable.
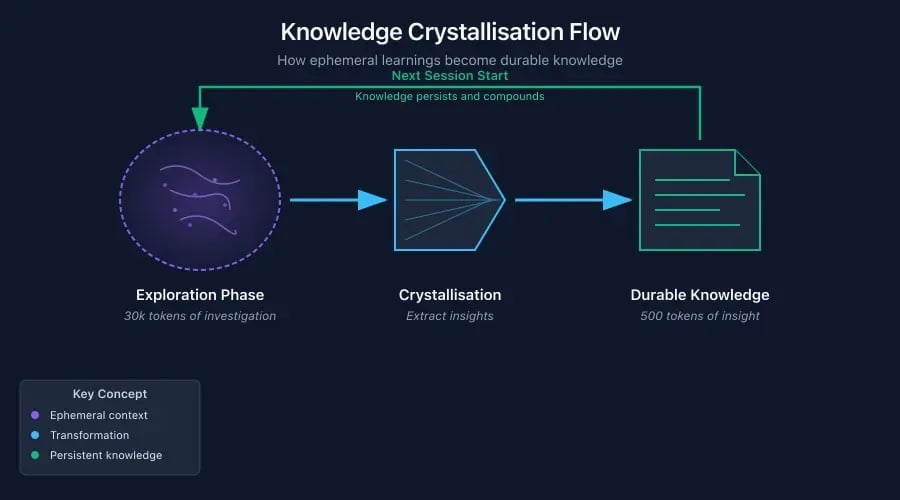
You might call these things "thoughts," but there are better names:
|
Name |
Vibe |
|---|---|
|
Insights |
Wisdom extracted from exploration |
|
Learnings |
Knowledge gained through work |
|
Memory Crystals |
Compressed, durable knowledge structures |
|
Distillations |
Essence from verbose exploration |
"Insights" or "Learnings" works best: clear, unpretentious, and they convey that this is extracted knowledge, not raw data.
The Memory Bank Pattern
Cline popularised a structured approach with dedicated files:
memory-bank/
├── projectbrief.md # What is this project?
├── productContext.md # Business/user perspective
├── systemPatterns.md # Architecture decisions
├── techContext.md # Dev environment & stack <
├── activeContext.md # Current focus area
└── progress.md # Status tracking 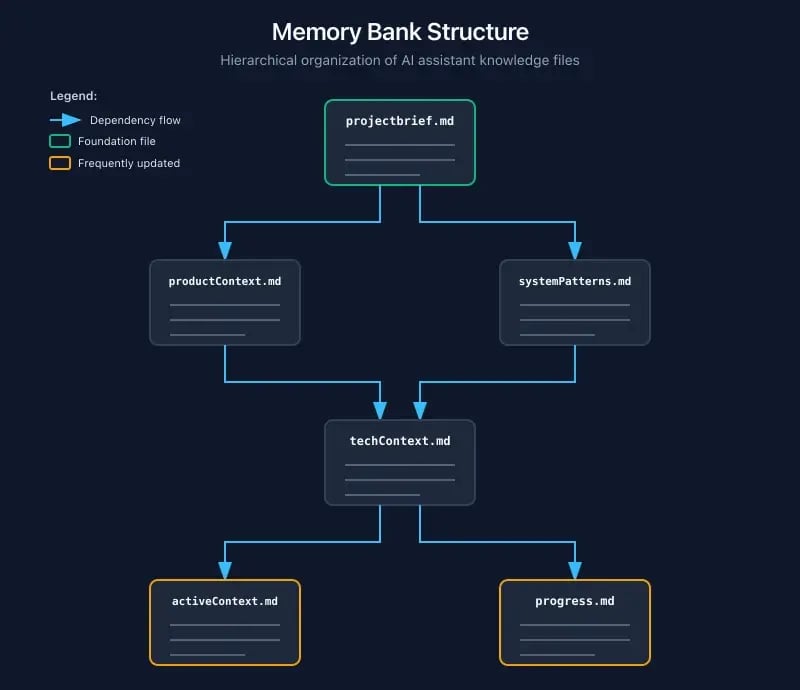
The workflow is dead simple:
- Start session: Read memory bank files
- Do work: Context accumulates as normal
- End session: Update relevant memory bank files
Your AI starts each session with project knowledge instead of a blank slate. The upfront token cost is small (a few hundred tokens) compared to re-discovering everything.
CLAUDE.md: Your Project's Brain
Claude Code has a built-in mechanism for this: CLAUDE.md. It's read automatically at session start and treated as high-priority instructions.
A solid example:
# Project: E-Commerce Platform
## Stack
- Next.js 14 with App Router
- PostgreSQL via Prisma
- Redis for sessions
## Commands
- `npm run dev` — Dev server (port 3000)
- `npm test` — Jest tests
- `npm run db:migrate` — Run Prisma migrations
## Gotchas
- Auth uses localStorage fallback for Safari (ITP issues)
- Don't modify /legacy — it's load-bearing spaghetti
- Tests require DATABASE_URL env var
## Current Focus
Migrating from JWT to session-based auth.Here's the key insight from HumanLayer:
"Claude will ignore the contents of your CLAUDE.md if it decides that it is not relevant to its current task."
This sounds bad but it's actually good. Anthropic intentionally made Claude deprioritise irrelevant instructions. It means you can include project-wide context without bloating every single task.
But it also means: make your CLAUDE.md universally relevant, not stuffed with edge cases.
The 150-200 Rule
HumanLayer's research uncovered a crucial constraint: LLMs can reliably follow about 150-200 instructions.
Claude Code's built-in system prompt already uses ~50 of those. That leaves you with maybe 100-150 before reliability drops.
Keep CLAUDE.md under 300 lines. HumanLayer's is under 60.
Quality over quantity. Every line should earn its place.
CLAUDE.md Anti-Patterns
Don't use Claude as a linter. This is tempting but wrong:
## Code Style (DON'T DO THIS)
- Use 2-space indentation
- Maximum line length 80 characters
- Always use semicolons
- Prefer const over let
- Use arrow functions for callbacks
- ... (50 more rules)
This bloats your context and degrades performance. Claude isn't a linter. It's an AI.
"Never send an LLM to do a linter's job."
Use actual linters (Biome, ESLint) and run them through Claude Code hooks. The linter enforces style; Claude focuses on logic.
Don't auto-generate. It's tempting to run /init and call it done. Don't.
"CLAUDE.md is one of the highest leverage points of the harness."
Manually craft every line. You know your project better than any auto-generator. The few minutes spent writing a good CLAUDE.md pays dividends across hundreds of sessions.
Don't list every possible command. Claude doesn't need a reference manual. It can read package.json. Include the non-obvious stuff, skip the obvious.
Progressive Disclosure
Instead of cramming everything into CLAUDE.md, use separate files loaded on demand:
docs/
├── building.md # How to build & deploy
├── architecture.md # System design
├── conventions.md # Code patterns we use
└── testing.md # Test strategy & setup
Then in CLAUDE.md:
## Documentation
- Read `docs/architecture.md` when working on system design
- Read `docs/testing.md` before writing tests
- Read `docs/conventions.md` for code review
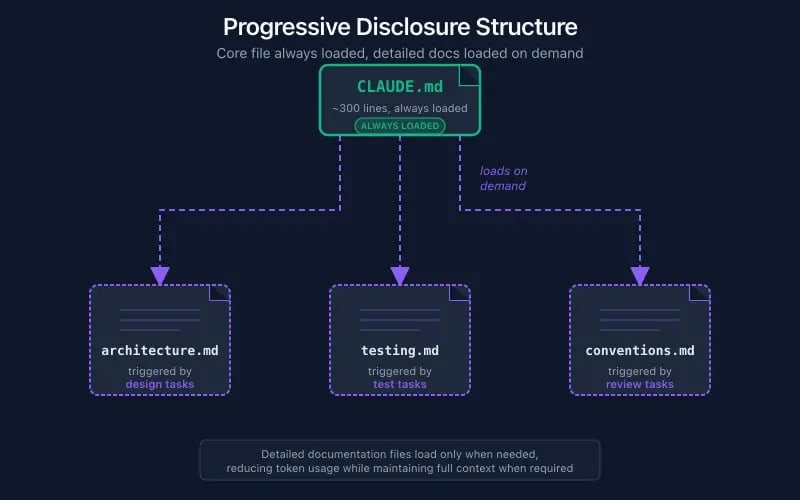
Context is loaded when needed, not upfront. Your baseline stays lean.
Session Hygiene
Even with great knowledge management, sessions get bloated. Here's how to stay clean.
The /compact command. When context is getting full, /compact compresses your conversation. It keeps important stuff, drops the noise.
Timing matters: compact at 70%, not 90%.
Why? You need room to finish your current task. If you compact at 90% and the task needs another 15% of context, you're stuck.

The /clear command. Switching tasks? Use /clear to reset context within your session. Less disruptive than starting a new session. Good for "I'm done with feature X, now working on feature Y."
Just start fresh. Real talk: if you've been debugging something for an hour and want to switch to documentation, open a new chat.
It feels wasteful. It's not. Each fresh session has zero context rot, no "lost in the middle" issues, no cross-contamination from unrelated tasks.
The best context management is sometimes no context at all.
Iterative Refinement
Your CLAUDE.md should evolve. Here's the loop:
- Add an instruction
- Give Claude a task that relies on it
- Watch what happens
- Refine if it didn't work
- Commit so teammates benefit
Claude Code has a shortcut: press # during a session to add instructions that get incorporated into CLAUDE.md automatically. Use it when you discover something worth remembering.
Hierarchical Summarisation
As sessions progress, use layered approaches:
|
Age |
Treatment |
|---|---|
|
Last 10-15 messages |
Keep verbatim |
|
Earlier in session |
Compress to summaries |
|
Stable project facts |
Move to CLAUDE.md |
|
One-time learnings |
Memory bank files |
Research suggests: prefer raw > compaction > summarisation. Each step loses fidelity. Only summarise when you must.
Advanced Patterns
Now let's go deeper. Techniques for power users: controlling what flows into your context, running autonomous loops, and architectural patterns for production AI systems.
Backpressure: Controlling What Flows In
Here's something that sounds boring but matters a lot: most tool output is rubbish.
A typical test run dumps 200+ lines:
PASS src/utils/helper.test.ts
PASS src/utils/format.test.ts
PASS src/utils/validate.test.ts
PASS src/utils/parse.test.ts
PASS src/utils/transform.test.ts
... (195 more lines)
PASS src/components/Button.test.ts
Test Suites: 47 passed, 47 total
Tests: 284 passed, 284 totalThat's 2-3% of your context for information you could convey in one character: ✓
Backpressure means controlling what flows into your context from tool outputs. HumanLayer's philosophy:
"Deterministic is better than non-deterministic. If you already know what matters, don't leave it to a model to churn through 1000s of junk tokens to decide."
The run_silent() pattern. Wrap commands to filter their output:
run_silent() {
output=$("$@" 2>&1)
if [ $? -eq 0 ]; then
echo "✓" # Success: one character
else
echo "$output" # Failure: full output for debugging
fi
} Success: just ✓. Claude knows tests passed, that's all it needs. Failure: full output. Claude needs details to debug.
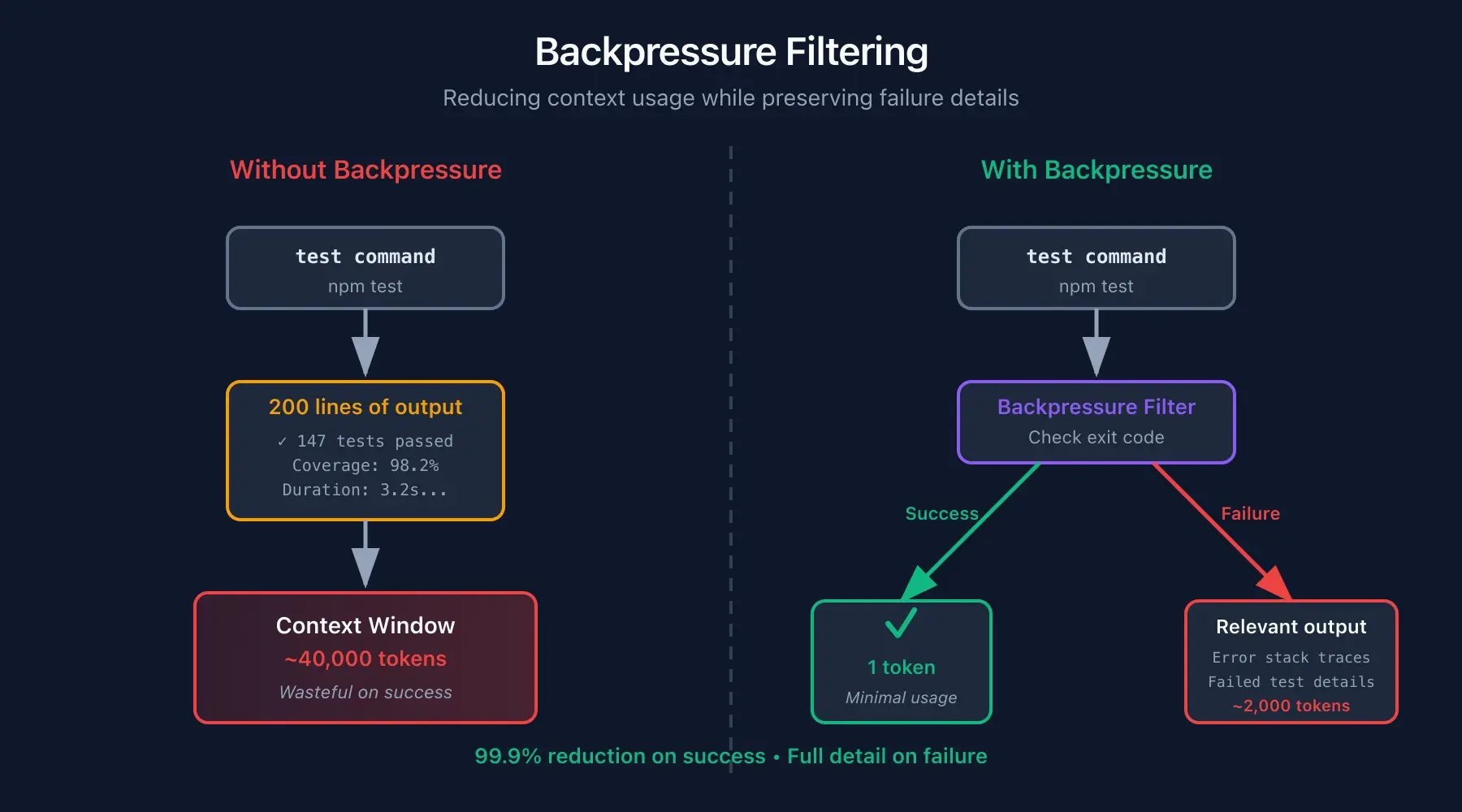
More backpressure techniques:
Use failFast modes:
pytest -x # Stop on first failure
jest --bail # Same for JestSurface one failure at a time. Fix it, run again. No need to load 47 failures into context.
Filter stack traces:
# Strip timing info, generic frames
your_command 2>&1 | grep -v "^\s*at " | grep -v "ms$" Claude Code hooks. You can automate this with pre/post command hooks. Filter output before it ever hits context.
The ROI here is real. HumanLayer's take:
human time managing agents in bloated contexts costs 10x more than setting up backpressure upfront. Spend 30 minutes on wrapper scripts. Save hours of context management.
The Ralph Loop
Here's a completely different approach to the Dumbzone problem: what if you just didn't manage context at all?
Created by Geoff Huntley in 2025, the "Ralph Wiggum Technique" is beautifully simple:
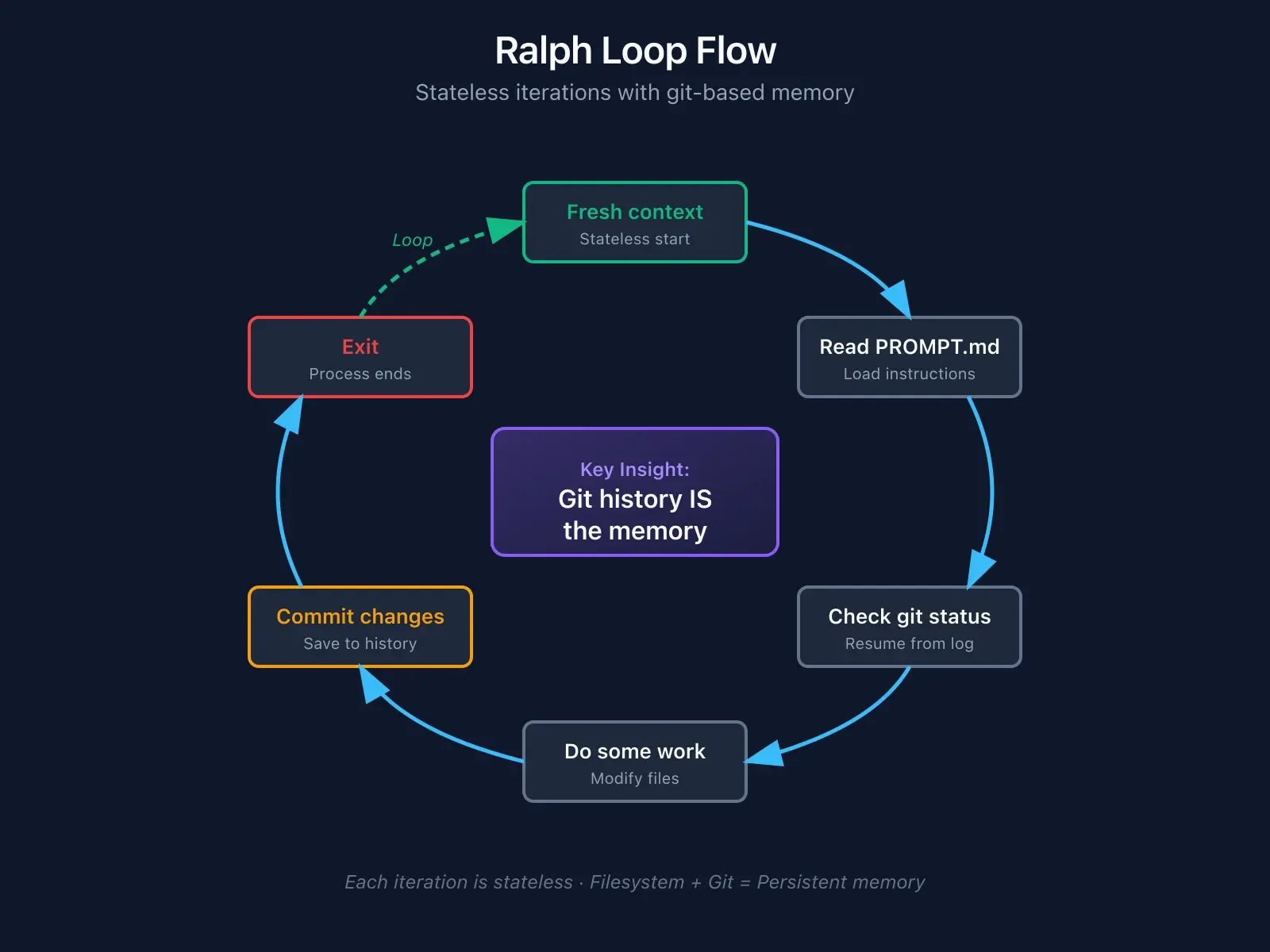
while :; do cat PROMPT.md | claude-code ; done That's it. Run Claude in a loop. Each iteration gets a fresh context. Progress tracked through git.
Why is it called Ralph Wiggum? From The Simpsons, Ralph is perpetually confused, always making mistakes but never stopping. That's the vibe.
"The technique is deterministically bad in an undeterministic world."
AI agents are probabilistic. They don't always make the same decision twice. They hallucinate. They take wrong turns.
But in a loop, failures become predictable. You know the agent will fail sometimes. Fine. The loop catches it, tries again.
It's better to fail predictably and recover automatically than to succeed unpredictably and need manual intervention.
How Ralph preserves context. Instead of cramming knowledge into a context window:
- Git history: Previous changes visible via
git diffandgit log - File state: The agent reads actual files, not stale conversation history
- PROMPT.md: Clear specifications persist across iterations
- Fresh context: Each iteration starts clean, zero Dumbzone risk
The filesystem is the memory. Git is the log. Each agent instance is stateless.
When to use Ralph:
Good fit:
- Clear objectives with defined success criteria
- Iterative refinements (upgrading deps, refactoring patterns)
- Tasks where "keep going until done" makes sense
- Long-running autonomous work
Not good for:
- Exploratory work without clear goals
- Tasks requiring reasoning chains across iterations
- When you're watching the API bill nervously
The results from the community are wild. Real examples: $50k contract completed for $297 in API costs. A 14-hour autonomous session upgrading React 16 to 19. A complete programming language generated overnight. Multiple repos shipped while developers slept.
The overbaking problem. Leave Ralph running too long and weird things happen. One user reported their agent spontaneously added cryptographic features nobody asked for. This isn't a bug, it's emergent behaviour from extended iteration. Set clear stopping conditions.
Cost awareness. A 50-iteration loop can run $50-100 depending on context per iteration. Start small until you understand the economics.
The 12 Factor Agents Framework
HumanLayer wrote a manifesto for production AI systems. Three factors matter most for context management.
Factor 3: Own Your Context Window
"Control how information is structured and presented. Don't let frameworks abstract this away."
Most frameworks hide context management. That's fine for demos, dangerous for production. You need to know what's going into context, how it's structured, and when it gets evicted.
If your framework doesn't give you this visibility, find a different framework.
Factor 10: Small, Focused Agents
"Keep agents to 3-20 steps handling specific domains rather than monolithic systems."
Big agents with long contexts "spin out trying the same broken approach over and over." The solution isn't a bigger context window. It's smaller agents.
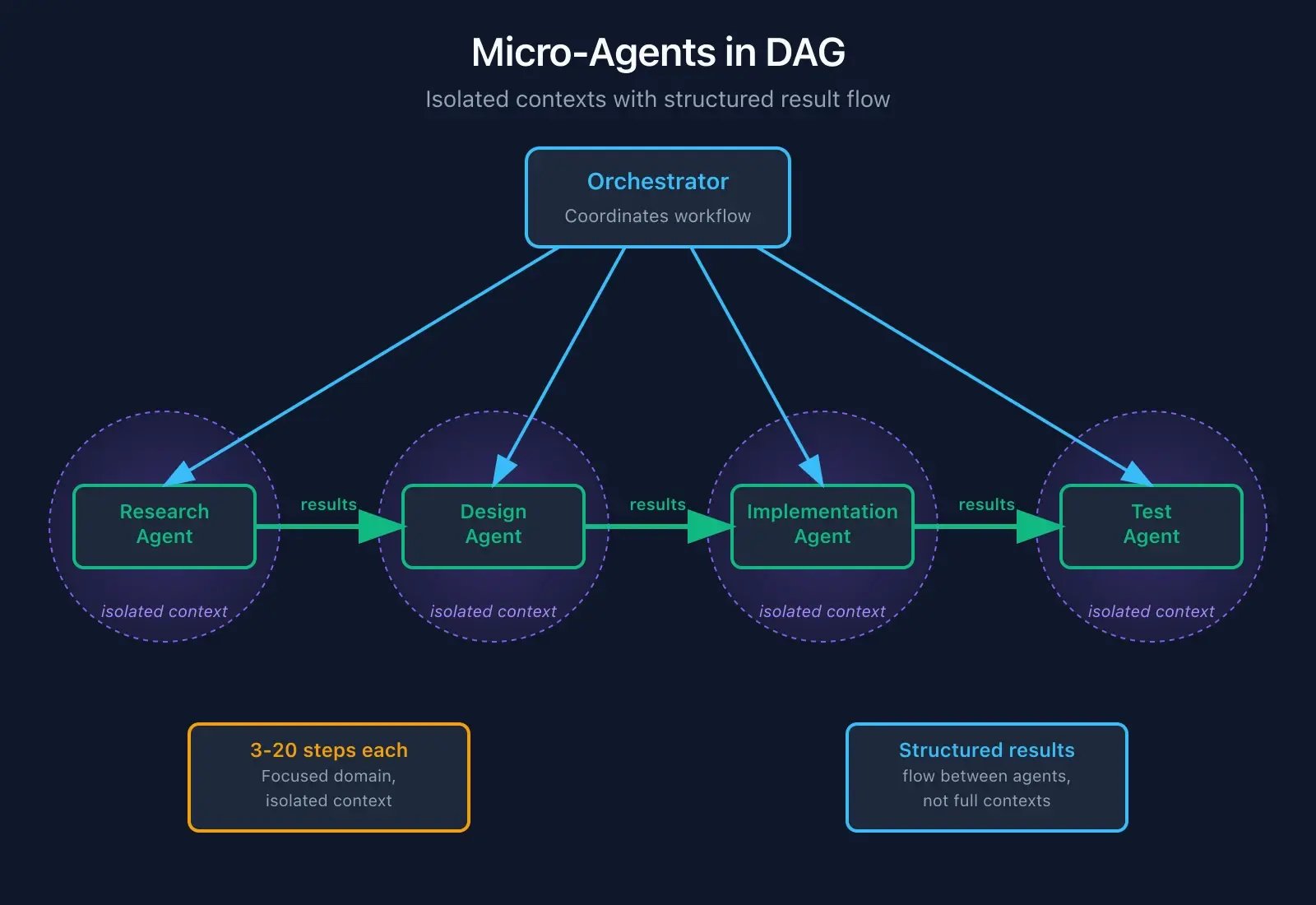
Embed micro-agents in a DAG (directed acyclic graph): the orchestrator decides what needs doing, specialised agents handle focused tasks, results flow between agents (not full contexts), and each agent stays in its smart zone.
Factor 12: Stateless Reducer Pattern.
"Design agents as functions transforming state deterministically. Don't rely on conversation history for critical state."
Conversation history is unreliable. The middle gets ignored. Context rots. Tokens overflow.
Instead: use an external state store (database, files, git). The agent reads state, performs action, writes state. No dependence on conversation memory for anything critical.
This is why Ralph works. The agent is stateless. Git is the state.
Putting It All Together
Here's how these patterns combine:
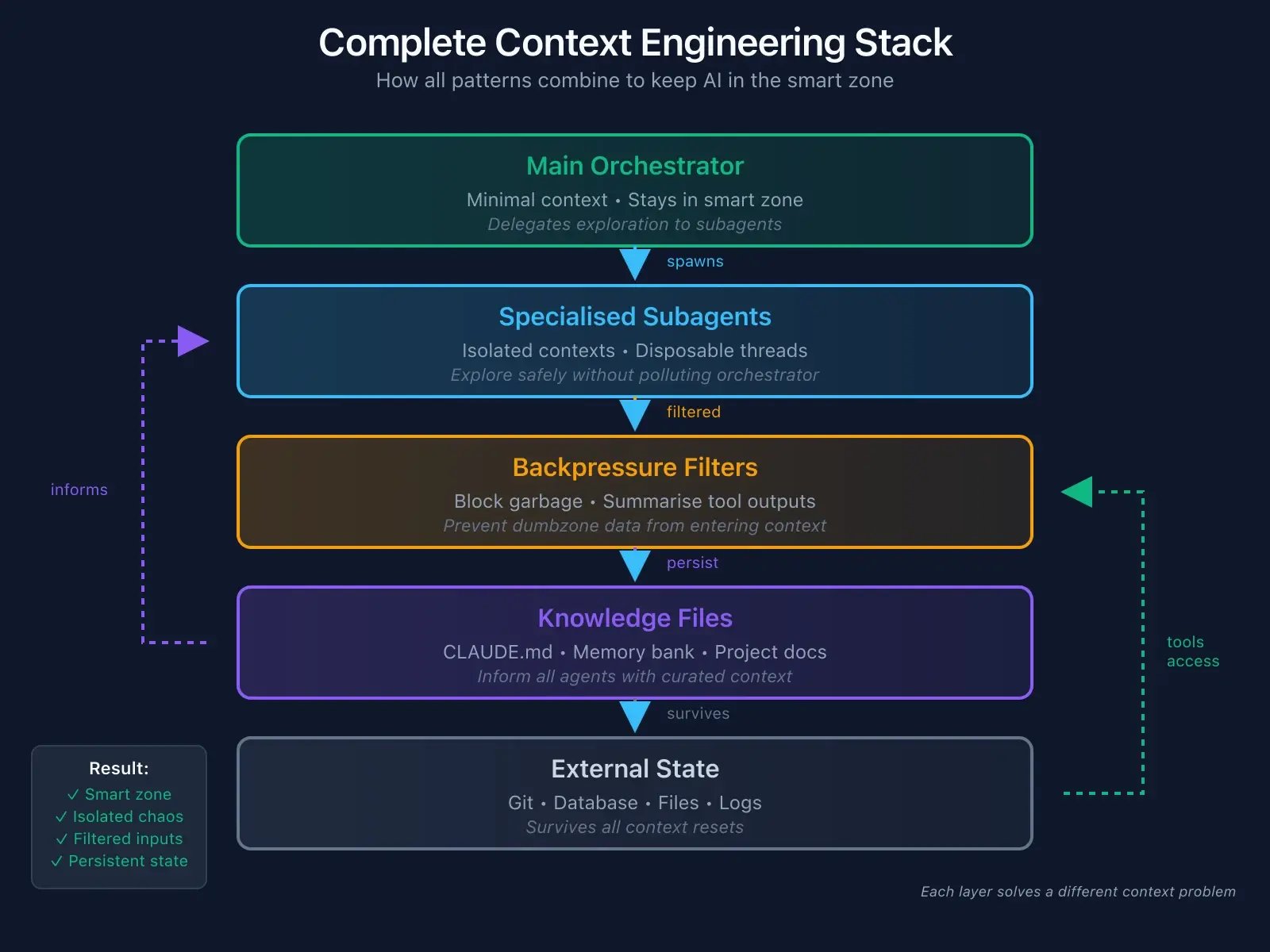
The orchestrator stays in the smart zone. Subagents handle exploration in isolation. Backpressure filters garbage before it enters context. Knowledge files persist learnings across sessions. External state survives everything.
You're not fighting the Dumbzone. You're engineering around it.
Practical Cheatsheet
Starting a session:
- Check the context meter and do a fresh start if above 50%
- Ensure CLAUDE.md is current
- Review memory bank files
- Decide: subagents for research? Ralph for iteration?
During work:
- Explore agent for investigation
- Filter verbose tool outputs
- Crystallise insights to files
- Compact at 70%
- Clear when switching tasks
Ending a session:
- Update CLAUDE.md with new learnings
- Update memory bank files
- Commit everything
- Consider: what will future you need?

Key Takeaways
The Dumbzone is real: Performance degrades sharply after 40% context usage. Stay under 75k tokens, watch for symptoms like instruction amnesia and context bleed.
- Subagents isolate exploration: 30 tokens of insight instead of 30,000 tokens of investigation. Scope tools intentionally, define done clearly, parallelise where possible.
- Crystallise knowledge: Memory bank files and a carefully crafted CLAUDE.md persist learnings across sessions. Keep it under 300 lines. Every line earns its place.
- Control backpressure: Filter verbose tool output before it hits context. Success = ✓. Failures get full details. Spend 30 minutes on wrapper scripts, save hours of context management.
- Consider Ralph: Sometimes the right answer is a fresh context every iteration with git as the memory. Fail predictably, recover automatically.
- Small agents beat big contexts: 3-20 step focused agents in a DAG, each in their smart zone, passing structured results rather than full context.
- Own your context window: It's an engineering discipline. Know what's going in, how it's structured, and when it gets evicted.
Final Thought
The context window isn't just a technical constraint. It's a forcing function for clarity.
When you can't dump everything in, you have to decide what matters. When you have to crystallise learnings, you actually think about what you learned. When you design small focused agents, you clarify what each piece should do.
The Dumbzone exists. But escaping it makes you a better engineer.